
浏览器引擎原理
浏览器内核
- Trident:微软开发,IE 浏览器使用,Edge 浏览器已经转向 Blink;
- Webkit:苹果基于 KHTML 开发,用于 Safari,Chrome 之前也在使用;
- Blink:谷歌基于 Webkit 开发,目前应用于 Chrome、Edge、Opera 等;
渲染引擎
渲染引擎决定了浏览器如何显示网页的内容以及页面的格式信息。
解析 HTML,遇到 script、style 会停止解析 HTML,优先加载 JS 代码和 CSS 代码。
所以建议:
- style 放最前,避免页面重绘。
- script 放最后,避免白屏等待过久。

JavaScript 引擎
专门处理 JavaScript 代码的虚拟机、解释器,用来解释执行 JS 代码。
- SpiderMonkey:第一款 JavaScript 引擎,由 JS 之父开发
- Chakra:微软开发,用于 IE 浏览器
- JavaScriptCore:苹果开发,WebKit 中的 JS 引擎
- V8:谷歌开发的性能强大的 JS 引擎
浏览器内核、渲染引擎和 JS 引擎的关系
以前内核的概念包括渲染引擎与 JS 引擎,现在习惯直接称渲染引擎为内核,JS 引擎独立。
- 以前称 Chrome 浏览器使用 Chromium 内核,blink 渲染引擎,V8 JS 引擎。
- 现在称 Chrome 浏览器使用 blink 内核,V8 JS 引擎。
编译型语言与解释型语言
编译型语言与解释型语言:
- 编译型语言:在代码执行前,预编译代码转换成机器语言,每次执行时不用重新编译。编译器生成的目标程序是面向特定平台。
- 解释型语言:不预编译代码,在执行代码前先解释转换成机器语言再执行,每次执行时都需要先逐行解释再逐行运行。解释器自己执行源程序,不依赖于某一平台。
- 解释型语言的执行速度要慢于编译型语言,但跨平台性好。
比如:最初的 C 和 C++ 都是编译型语言,而最初的 JavaScript 是解释型语言。编译器启动速度慢,执行速度快。而解释器的启动速度快,执行速度慢。不过随着即时编译(Just-in-time compilation,JIT),一种混合使用编译器和解释器的技术的发展,大部分语言都可以即时编译了。
现在应尽量避免将编程语言划分为编译型或解释型语言。 详见:Java 是编译型语言还是解释型语言?
为了提高 JS 的执行效率,浏览器厂商都在不断努力。目前性能最高的 JS 引擎是 V8 引擎,它引入了 Java 虚拟机和 C++ 编译器的众多技术,实现了即时编译,V8 引擎属于 JIT 编译器。
V8 引擎的原理
V8 的名字来源于汽车的“V 型 8 缸发动机”(V8 发动机)。V8 发动机主要是美国发展起来,因为马力十足而广为人知。V8 引擎的命名是 Google 向用户展示它是一款强力并且高速的 JavaScript 引擎。
V8 是 Google 用 C++ 编写的开源高性能 JavaScript 和 WebAssembly 引擎,它用于 Chrome 和 Node.js 等。
V8 引擎主要模块有:
- Parser: 解析器,负责将源代码解析成
AST(Abstract Syntax Tree) 抽象语法树 - Ignition: 解释器,负责将
AST抽象语法树转换成字节码并执行,并且会监听、标记热点代码 - TurboFan: 优化编译器,负责将热点代码编译成比字节码更高效的机器码并执行
- Orinoco: 垃圾回收器,负责回收程序不需要的内存空间
V8 引擎主要流程
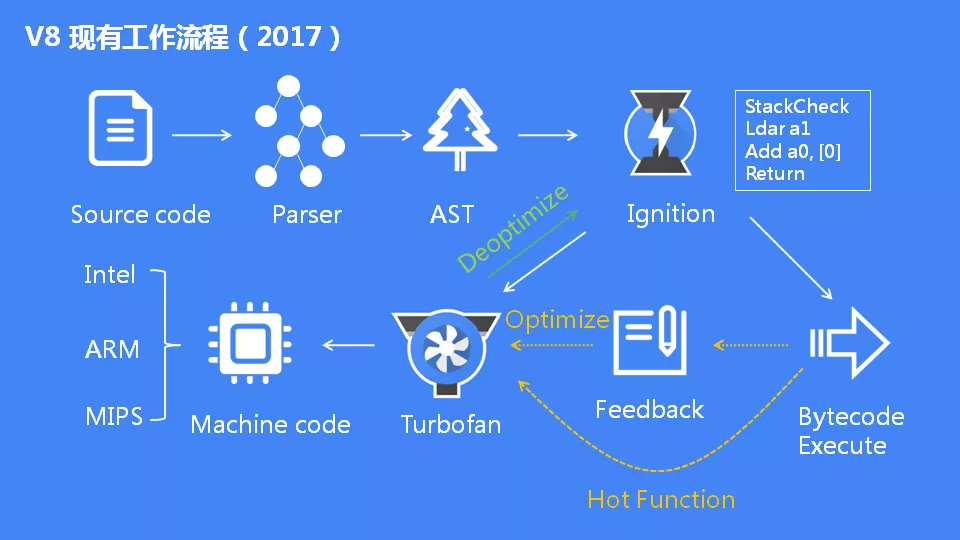
图源:极客时间《图解 Google V8》
主要流程
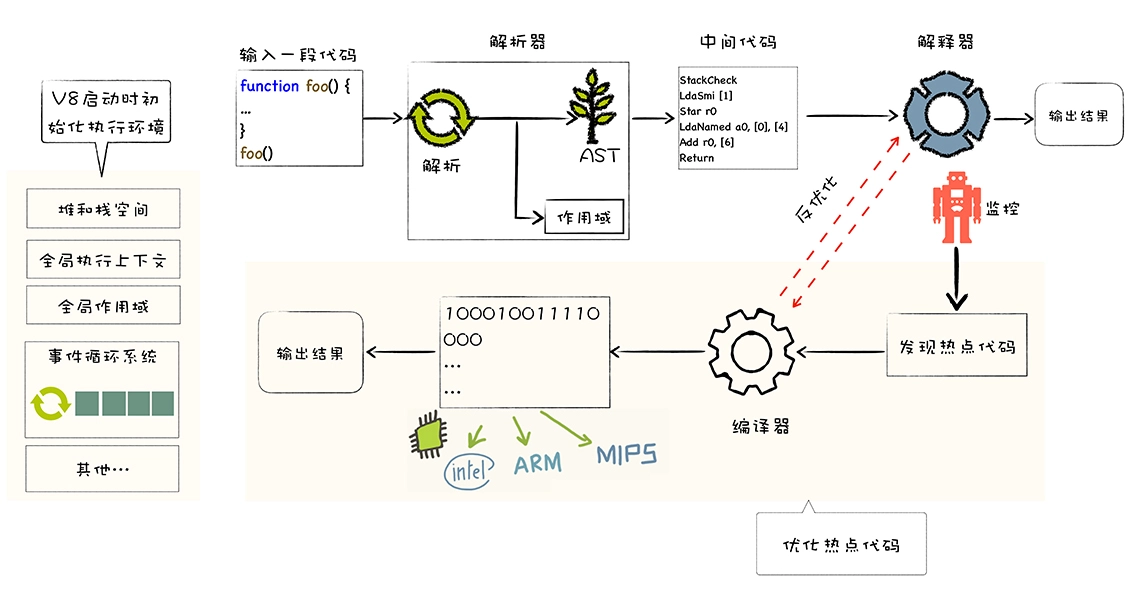
Parser解析器:JS 源代码经过解析器的词法分析(将 JS 代码拆分成一个个词法单元token)和语法分析(将词法单元token根据语法规则组合成AST抽象语法树 ),分析过程中如果语法有错,会抛出语法错误。Ignition解释器:AST通过Ignition解释器转化为byte code字节码并执行。在执行过程中,如果发现重复执行多次的代码,则标记为热点代码,将热点代码交给TurboFan编译器处理。TurboFan优化编译器:编译器拿到解释器标记的热点代码后,把它编译为更高效的机器码储存起来,等到下次再执行到这段代码时,就会用现在的机器码替换原来的字节码进行执行,这样大大提升了代码的执行效率。当一段代码不再是热点代码后,进行deoptimization去优化处理还原成字节码。
Parser 解析器
Parser 解析器负责将源代码转换成 AST 抽象语法树。在转换过程中有两个重要的阶段:词法分析(Lexical Analysis)和语法分析(Syntax Analysis)。
在 Parser 解析器将源码转化为 AST 之前,有一个 Scanner 扫描器的词法分析。过程图及描述如下:
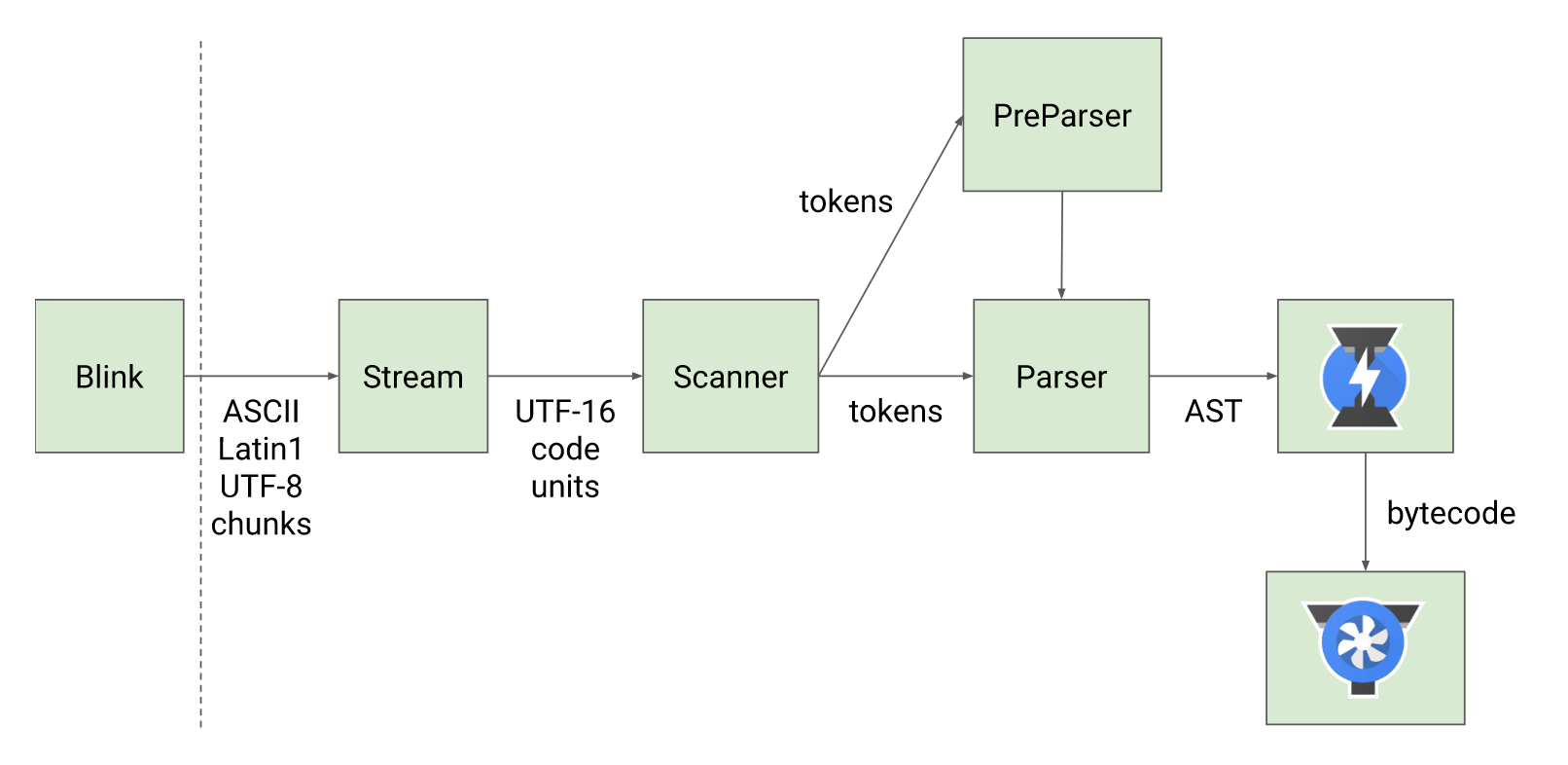
Blink渲染引擎将源码交给 V8 引擎,Stream获取到源码并且进行编码转换Scanner扫描器会进行词法分析,词法分析会将代码转换成tokens- 接下来
tokens会被转换成AST树,经过Parser解析器和PreParser预解析器:需要马上执行的 JS 代码进行解析,不需要马上执行的则进行预解析(又称 延迟、惰性解析)。 - 生成
AST树后,会被Ignition解释器转成字节码并执行。
词法分析生成许多个词法单元 tokens
let message = 'hi'
Tokens
[
{
type: 'Keyword',
value: 'let'
},
{
type: 'Identifier',
value: 'message'
},
{
type: 'Punctuator',
value: '='
},
{
type: 'String',
value: "'hi'"
}
]
AST
{
"type": "Program",
"body": [
{
"type": "VariableDeclaration",
"declarations": [
{
"type": "VariableDeclarator",
"id": {
"type": "Identifier",
"name": "message"
},
"init": {
"type": "Literal",
"value": "hi",
"raw": "'hi'"
}
}
],
"kind": "let"
}
],
"sourceType": "script"
}
并不是所有的 JavaScript 代码,在一开始时就会被执行。那么对所有的 JavaScript 代码进行解析,必然会影响网页的运行效率; 所以 V8 引擎就实现了 Lazy Parsing(惰性解析)的方案,它的作用是将不必要的函数进行预解析,也就是只解析暂时需要的内容,而对函数的全量解析是在函数被调用时才会进行; 在一个函数 outer 内部定义了另外一个函数 inner,那么 inner 函数就会进行预解析;
Ignition 解释器
将抽象语法树转换为字节码并执行;同时收集 TurboFan 优化编译器所需的信息,比如函数参数的类型(使用 TS 约束变量类型可以提高编译效率的原因)。
TurboFan 优化编译器
TurboFan 拿到 Ignition 标记的热点代码后,会先进行优化处理,然后将优化后字节码编译成更高效的机器码存储起来。下次再次执行相同代码时,会直接执行相应的机器码,这样就在很大程度上提升了代码的执行效率。
当一段代码不再是热点代码后,TurboFan 会进行去优化的过程,将优化编译后的机器码还原成字节码,将代码的执行权利交还给 Ignition。
拓展阅读:JavaScript 深入浅出第 5 课:Chrome 是如何成功的? 了解下 V8 引擎的历史
- 机器码、字节码、汇编语言区别
- 机器码(machine code):机器语言指令,是电脑的 CPU 可直接解读的 0 1 二进制序列。
- 字节码(byte code):是一种包含执行程序、由一序列 op 代码/数据对 组成的二进制文件。是一种中间码,它比机器码更抽象,需要直译器转译后才能成为机器码的中间代码。
- 汇编语言:汇编经过转译最终也会成为机器码,汇编语言可以简单理解为机器语言的助记